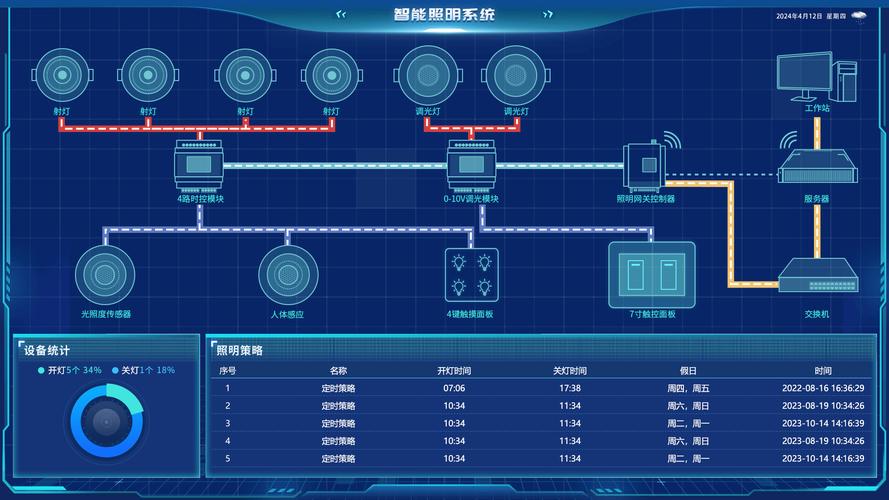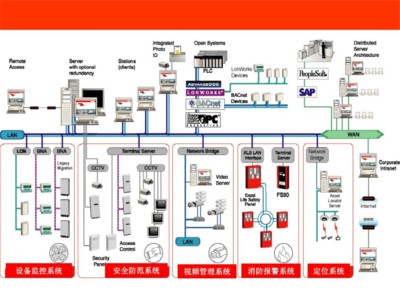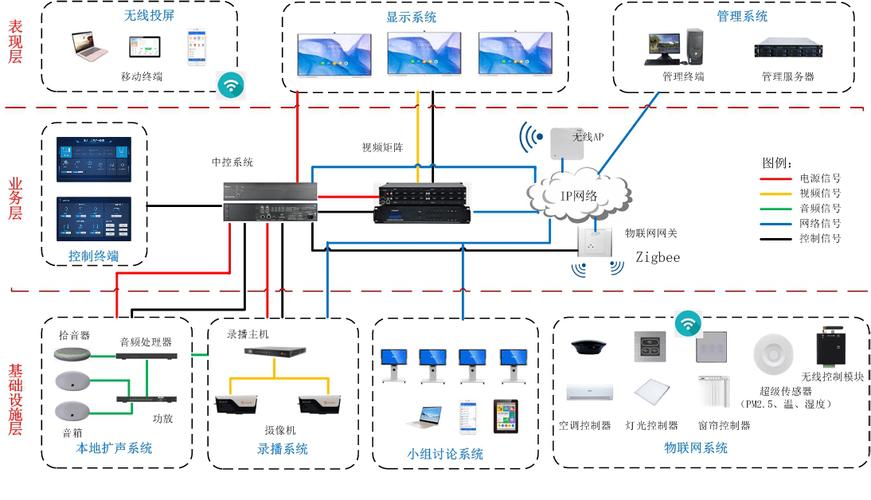
隨著教育信息化步入深度融合階段,傳統的教室管理模式已難以適應現代化教學的需求。廣凌智慧教室解決方案應運而生,其核心便是一套高度集成的智慧教室管理中控系統。該系統并非簡單的設備堆砌,而是通過先進的技術架構,將多媒體設備、網絡通信與自動化控制設備無縫融合,構建了一個智能、高效、便捷的一體化教學與管理新生態。
一、 三位一體:中控系統的集成核心
廣凌智慧教室管理中控系統扮演著“神經中樞”的角色,其強大之處在于對三大關鍵板塊的深度集成:
- 多媒體設備集成: 系統統一管控投影機/智慧屏、實物展臺、功放音響、錄播主機等所有視聽設備。教師可通過一塊觸摸屏或移動終端,實現一鍵上下課、信號源切換、音量調節、畫面凍結等操作,告別繁瑣的多遙控器操作,讓教師專注于教學本身。
- 網絡通信集成: 系統深度融合有線與無線網絡,不僅保障各類設備穩定聯網,更實現了教學數據的實時傳輸與交互。它能與校園云平臺、資源庫、教學軟件無縫對接,支持屏幕廣播、分組互動、在線評測等網絡化教學功能,為翻轉課堂、混合式教學提供堅實支撐。
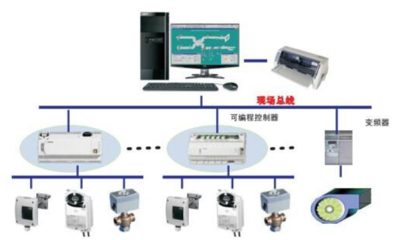
- 自動化控制設備集成: 這是系統實現“智慧”的關鍵。通過集成物聯網技術,中控系統能夠聯動控制教室內的空調、燈光、窗簾、門禁、安防傳感器等環境設備。系統可預設“上課”、“自習”、“投影”、“離場”等多種場景模式,一鍵觸發,自動將燈光調至合適亮度、窗簾開合、空調設定到舒適溫度,營造最佳教學環境的實現能源的智能管理。
二、 自動化控制:智慧體驗的無聲引擎
文中特別指出的“自動化控制設備”,是智慧教室從“功能化”邁向“智能化”的質變點。廣凌系統中控對其的集成主要體現在:
- 環境自適應: 通過光照傳感器、人體紅外傳感器、溫濕度傳感器的數據反饋,系統能自動調節燈光和空調,實現“人來燈亮、人走燈滅”,恒溫舒適,全程無需人工干預。
- 流程自動化: “上課鈴響,燈光自動緩緩亮起,窗簾閉合,投影機開啟,講臺設備通電……”這一系列連貫動作,均可由中控系統根據課表時間或觸發指令自動完成,極大提升了管理效率和教學儀式感。
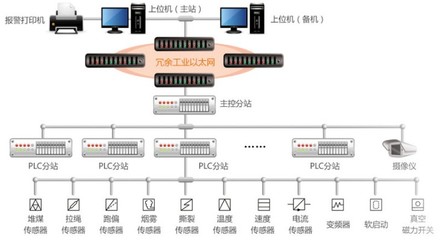
- 安防與能耗管理: 門禁系統與課表聯動,實現授權出入;課后,系統自動檢測無人狀態,延時關閉所有非必要設備,并生成能耗報表,助力綠色校園建設。
三、 價值升華:超越集成的綜合效益
廣凌智慧教室管理中控系統的最終價值,遠超設備集成的便利性。它通過一體化平臺:
- 賦能教師: 降低技術使用門檻,簡化操作流程,讓教師能輕松駕馭復雜的技術環境,創新教學方法。
- 提升體驗: 為學生和教師提供高度舒適、沉浸、互動的教學環境,提升學習專注度與教學效果。
- 精細管理: 為管理人員提供遠程監控、批量控制、數據統計、故障預警等功能,實現教室資產的數字化、精細化運維。
- 數據驅動: 作為數據匯聚節點,為教學分析、空間利用率評估、設備生命周期管理等提供數據基礎,驅動教學與管理的科學決策。
總而言之,廣凌智慧教室管理中控系統通過深度集成多媒體、網絡與自動化控制設備,打破了信息孤島,將物理教室空間轉化為一個能感知、會思考、可協同的智慧生命體。它不僅是設備控制的指揮官,更是教學創新的賦能者、管理效率的提升者和數據價值的挖掘者,正引領著未來教室的變革方向,為建設高質量的教育現代化體系奠定堅實的技術基石。